MongoDB 21.05.26
in Dev
MongoDB : NoSQL 도큐먼트 데이터베이스. 데이터는 도큐먼트의 형태로 저장.
NoSQL DB : 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소
Atlas Cloud : MongoDB에서는 아틀라스(Atlas)를 사용하여 클라우드에서 데이터베이스를 설정
인스턴스 : 로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스입니다.
클러스터 : 데이터를 저장하는 서버 그룹
레플리카 세트 : 동일한 데이터를 저장하는 소수의 연결된 머신들은 머신 중 하나에 문제가 발생하더라도 데이터가 그대로 유지되도록 합니다.
MongoDB Document
도큐먼트(Document) : 필드 - 값 쌍으로 저장된 데이터
필드(Field) : 데이터포인트를 위한 고유한 식별자
값(Value) : 주어진 식별자와 관계된 데이터
컬렉션(Collection) : 도큐먼트들의 모음
<!-- Document Syntax -->
{
필드 : 값,
필드 : 값,
}
{} 중괄호로 감싸기
필드와 값이 콜론(:)으로 분리, 필드와 값을 포함하는 쌍은 , 쉼표로 나누기
필드도 문자열이므로 "" 쌍따옴표로 감싸기
<!-- Document ex -->
{
"name" : "creamer",
"job" : "dev"
}
MongoDB의 도큐먼트로 구성된 저장소로 일반적으로 도큐먼트 간의 공통 필드가 있습니다. 데이터베이스 당 많은 컬렉션이 있고 컬렉션 당 많은 도큐먼트가 있을 수 있습니다.
JSON vs BSON
MongoDB의 데이터는 BSON의 형태로 저장이 되고, 보통 읽기 쉬운 JSON의 형태로 출력
JSON : 사용하기 쉽지만 텍스트 형식이기 때문에 파싱이 매우느리고 메모리 사용에 비효율적이며 기본 데이터 타입만 지원하므로 데이터 타입에 제한.
BSON(Binary JSON) : 이진법 기반 표현법. JSON의 단점 보완. 빠르고 가벼우며 메모리 사용 효율적, 더 많은 데이터 타입 사용 가능.
MongoDB는 BSON으로 데이터를 저장하고, JSON의 형태로 조회할 수 있습니다. BSON은 JSON 보다 파싱(parse)하는데 더 빠르고, 저장하기에 가볍습니다. JSON은 BSON보다 더 적은 데이터 타입을 지원합니다.
데이터 가져오기 / 내보내기
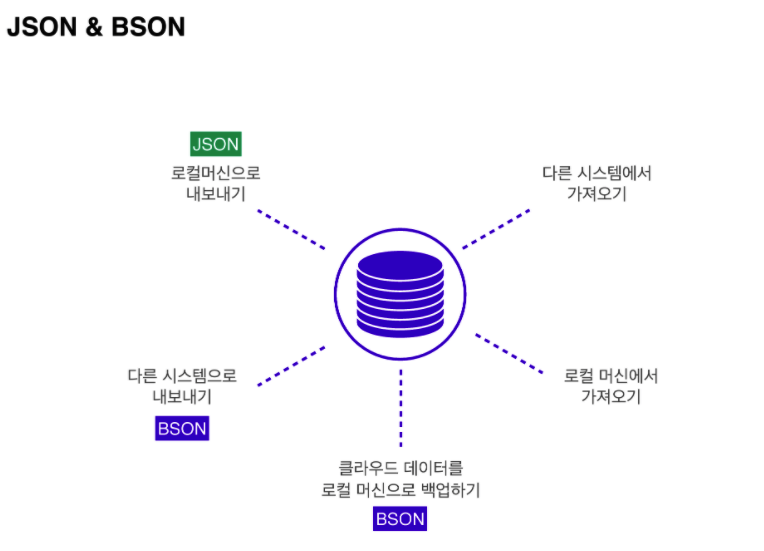
mongoDB를 사용하여 데이터를 어떤 로컬 장치나 다른 시스템으로 내보내거나, 혹은 가져오기.
JSON
- mongoimport(데이터 클러스터로 가져오기)
<!-- syntax -->
mongoimport --uri"<Atlas Cluster URI>" [--drop=<파일이름>.json] [--collection 컬렉션이름]
기존에 있는 데이터를 삭제하기 위한 옵션인 drop 쿼리문은 선택적으로 사용 가능
json 뿐만아니라 csv와 같은 데이터 형식으로도 가능.
컬렉션 이름을 지정하는 등 부가적인 옵션 추가 가능.
- mongoexport(데이터 로컬로 내보내기)
<!-- syntax -->
mongodump --uri"<Atlas Cluster URI>" --collection=<컬렉션 이름> --out=<파일 이름>.json
BSON
- mongorestore(데이터 클러스터로 가져오기)
<!-- syntax -->
mongorestore --uri"<Atlas Cluster URI>" [--drop dump]
기존에 있는 데이터를 삭제하기 위한 옵션인 drop 쿼리문은 선택적으로 사용 가능
- mongodump(데이터 로컬로 내보내기)
<!-- syntax -->
mongodump --uri"<Atlas Cluster URI>"
MongoDB CRUD
MongoDB의 모든 도큐먼트는 _id 필드를 기본 값으로 가지고 있다.
_id 필드의 값은 각 도큐먼트를 구분하는 역할 :
도큐먼트 내 필드와 값이 같은 경우 _id 값이 다르면 서로 다른 도큐먼트로 간주.
도큐먼트 내 필드와 값이 다르다고 하더라도 _id 필드의 값이 같다면 서로 같은 도큐먼트로 여겨 에러 발생.
CREATE
- insert() : 도큐먼트 삽입
<!-- syntax -->
db.컬렉션이름.insert(삽입하고자하는 다큐먼트)
<!-- ex code : 단일 도큐먼트 삽입-->
코드 실행
db.users.insert({"_id" : ObjectedID("1"), "name":"creamer", "job":"dev" })
결과
WriteResult ({"nInserted" : 0, "WriteError" : ...dup key...)}
nInserted는 삽입된 도큐먼트의 수를 의미. 0이면 삽입 실패
dup key 에러는 duplicate key. 즉 키가 _id가 중복되었기 때문에.
dup key 에러가 발생하면 _id 값을 적지않고 삽입 작업을 실행하면 dup key 에러가 발생하지 않는다.
db.users.insert({ "name":"creamer", "job":"dev" })
<!-- ex code : 컬렉션에 다수 도큐먼트 삽입: 배열 사용-->
db.users.insert([{ "name":"creamer", "job":"dev" }, { "name":"dreamer", "job":"artist" }])
<!-- ex code : 존재하지 않는 컬렉션에 도큐먼트 삽입-->
존재하지 않는 컬렉션에 도큐먼트를 넣는 경우, 컬렉션 생성 후 삽입
db.userss.insert({ "name":"creamer", "job":"dev" })
- 다수 도큐먼트 삽입 배열 사용 시 주의 사항 및 orderd
다량의 도큐먼트가 삽입 될 때, 삽입이라는 작업을 수행하기 위한 기본 프로세스가 배열 안의 리스트된 순서대로 진행. (orderd:true)
orderd : ordered:false 를 사용하면 순서에 상관 없이 고유한 _id를 가진 도큐먼트는 모두 컬렉션에 삽입
<!-- ex code 1 -->
db.fruits.insert([{ "fruit": "apple" }, { "fruit": "banana" }, { "fruit": "blueberries" }])
// _id 값이 주어지지 않았으므로 해당 데이터 모두 삽입. (_id 값은 컬렉션에서 자동으로 생성)
// apple, banana, blueberries 추가
<!-- ex code 2 -->
db.fruits.insert([{ "_id": 1, "fruit": "apple" },
{ "_id": 1, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 4, "fruit": "pineapple" }], { "ordered": true })
// ordered 필드의 값이 true이기 때문에, 배열 안의 인덱스 순서대로 insert 작업이 수행
// 그러나 _id 필드의 값이 같은 것이 있다면 duplicate key 에러가 발생
// 에러 발생 필드와 값 쌍 이후의 요소들는 추가 되지 않음
// apple만 추가
<!-- ex code 3 -->
db.fruits.insert([{ "_id": 1, "fruit": "apple" },
{ "_id": 1, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 4, "fruit": "pineapple" }], { "ordered": false })
// 두번째 인자 orderd 값이 false 이기 때문에
// 배열 내부의 요소의 순서에 상관 없이 고유한 _id의 값을 가진 도큐먼트는 모두 새로운 도큐먼트로 추가
// apple, blueberries, pineapple 추가
<!-- ex code 4 -->
db.fruits.insert([{ "_id": 1,"fruit": "apple" },
{ "_id": 2, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 3, "fruit": "pineapple" }])
// ordered 필드가 정해지지 않으면 true가 기본값으로 설정되고,
// 배열의 요소 순서대로 삽입되기 때문에 인덱스 0번부터 2번까지의 도큐먼트 3개가 새로운 도큐먼트로 추가
// apple, banana, pineapple 추가
READ
show dbs : 데이터베이스 리스트 보기
find(조건)
<!-- syntax -->
db.컬렉션이름.find(조건)
<!-- ex code : 조건에 맞는 데이터 전체 찾기 -->
db.users.find({"job":"dev"})
// JSON 형식으로 20개 도큐먼트만 출력.
// 다음 20개의 도큐먼트를 출력하기 위해서는 it 명령어 사용. (20개 이상인 경우에만 사용 가능)
<!-- ex code : 다수의 조건에 맞는 데이터 전체 찾기 -->
db.users.find({ "name":"creamer", "job":"dev"})
<!-- ex code : 무작위로 데이터 전체보기 -->
db.users.find()
- findeOne(조건)
<!-- ex code : 조건에 맞는 데이터 하나 찾기 -->
db.userss.findOne({ "name":"creamer", "job":"dev" })
<!-- ex code : 무작위로 데이터 하나 찾기 -->
db.userss.findOne()
- pretty() : 예쁘게 출력
<!-- syntax -->
cursor.pretty()
// cursor는 find 메소드를 실행해서 얻어낸 결과의 집합
- count() : 데이터의 수를 조회
<!-- syntax -->
db.컬렉션이름.find().count()
UPDATE
- updateMany() : 다수의 데이터 업데이트
<!-- syntax -->
db.컬렉션이름.updateMany({조건 도큐먼트}, {연산자 : 변경할 도큐먼트})
<!-- ex code : users 컬렉션에서 job(필드)의 값이 dev라면 salaly를 100 올려라 -->
// 실행
db.users.updateMany({"job" : "dev"}, {"$inc" : {"salaly": 100}})
// $inc는 연산자
// 응답 : 업데이트가 성공했고 3개의 데이터가 변경
{ "acknowledged": true, "matchedCount" : 3, "modifiedCount" : 3 }
// matchedCount : 조건을 충족하는 도큐먼트의 수
// modifiedCount : 수정된 도큐먼트의 수
- updateOne() : 하나의 데이터만 업데이트
<!-- syntax -->
db.컬렉션이름.updateOne({조건 도큐먼트}, {연산자 : 변경할 도큐먼트})
<!-- ex code : users 컬렉션에서 name(필드)의 값이 creamer라면 salaly를 10000000000으로 변경-->
// 실행
db.users.updateMany({"name" : "creamer"}, {"$set" : {"salaly": 10000000000}})
없는 필드를 작성한 경우 에러가 발생하지 않고 잘못 작성된 필드가 추가
배열 업데이트
db.테이블명.updateOne({업데이트할 도큐먼트를 결정하는 조건},
{"$push", {"서브도큐먼트를 삽입할 배열 타입의 값을 가지고 있는 필드" :
{"추가할 서브 도큐먼트"}}})
db.users.updateOne({"job" : "dev"},
{"$push", {"skills" :
{"back-end" : "몽고DB"}}})
- 필드가 존재하지 않으면 필드의 값으로 빈 배열을 생성하여, 그 안에 요소로 값을 추가합니다.
DELETE
- deleteMany() : 다수의 데이터 삭제
<!-- syntax -->
db.컬렉션이름.deleteMany(삭제할 도큐먼트를 결정하는 조건)
<!-- ex code -->
db.users.deleteMany("job" : "ceo")
- deleteOne()
<!-- syntax -->
db.컬렉션이름.deleteOne()(삭제할 도큐먼트를 결정하는 조건)
<!-- ex code -->
db.users.deleteOne("_id" : "15")
// deleteOne( )을 사용하는 경우, _id 값으로 쿼리해 온 도큐먼트를 삭제하는 것이 좋은 접근법
// _id 값으로 쿼리를 하지 않는다면, 검색 쿼리문에 다양한 도큐먼트가 적합할 수 있기 때문입니다.
- drop() : 컬렉션 삭제
show collections
// 컬렉션 리스트 보기
<!-- syntax -->
db.삭제할컬렉션이름.drop()
연산자
비교 연산자
비교 연산자를 사용하면 특정 범위 내에서 데이터를 찾을 수 있다.
비교 연산자를 지정하지 않으면 $eq가 기본 연산자로 사용됩니다.
- $eq : 같은지 판단 - Equal to
- $ne : 다른지 판단 - Not Equal to
- $gt : 큰지 판단 - Greater Than
- $gte : 크거나 같은지 판단 - Greater Than or Equal to
- $lt : 작은지 판단 - Less Than
- $lte : 작거나 같은지 판단 - Less Than or Equal to
<!-- syntax -->
{ field : { 연산자 : 값 } }
<!-- 여러 연산자를 동시에 사용 가능 -->
{ field : { 연산자 : 값 }, field: { 연산자 : 값 } }
<!-- ex code -->
{"age" : {"$lte" : 30 }}
논리 연산자
논리 연산자를 사용하면 데이터 검색을 보다 세분화 가능.
논리 연산자가 지정되지 않은 경우 $and가 기본 연산자로 사용되며, 동일한 연산자를 쿼리에 두 번 이상 포함해야 하는 경우, $and를 명시적으로 사용하고 배열안에 조건 쿼리를 담아준다.
- $and : 주어진 모든 쿼리절과 일치 여부 { $and : [{쿼리 조건1}, {쿼리 조건2}], ..}
- $or : 주어진 커리절 하나라도 일치 여부 { $or : [{쿼리 조건1}, {쿼리 조건2}], ..}
- $nor : 주어진 모든 쿼리절과 불일치 여부 { $nor : [{쿼리 조건1}, {쿼리 조건2}], ..}
- $not : 주어진 쿼리절과 불일치 여부 { $not: {쿼리 조건} }
표현 연산자
표현 연산자로 더 복잡한 쿼리를 작성할 수 있으며 도큐먼트 내의 필드를 비교 가능
또한 $는 필드의 값을 참조할 때에도 사용 가능
쿼리 내에서 집계 표현식(Aggregation Expression) 사용 가능
변수와 조건문을 사용 가능.
같은 도큐먼트 내의 필드들을 서로 비교 가능
<!-- ex code : 같은 곳에서 자전거를 대여 및 반납하고 1200초 이상 이용한 경우 데이터 찾기 -->
// Aggregation Expression 사용
{"$expr" : {
"$and" : [
{ "$gt" : ["$triptime", 1200 ]}
// $는 필드의 값을 참조할 때에도 사용 가능
// $triptime의 $는 triptime의 값을 뜻한다.
{ $eq" : ["$start station id", "$end station id" ] }
// $는 필드의 값을 참조할 때에도 사용 가능
// "$start station id"의 $는 연산자를 뜻하는게 아닌 start station id 필드의 값을 의미
]
}
}
// Aggregation Expression Syntax
{연산자 : {필드, 값}}
// MQL Syntax
{필드 : {연산자 : 값}}
배열 연산자
$push : 배열의 마지막 위치에 엘리먼트 삽입. 배열이 아닌 필드에 사용시 필드의 타입을 배열로 변경. 배열순서가 중요
$all : 배열 필드에 지정한 요소가 있는 모든 도큐먼트를 반환합니다
$size : 배열 길이를 기준으로 반환
<!-- syntax -->
<!-- ex code : 배열 필드가 숫자와 정확히 일치하는 모든 도큐먼트들이 있는 커서 반환 -->
{배열 필드 : {"$size" : 숫자}}
<!-- ex code : 배열 필드의 순서와 관계 없이 지정된 모든 요소가 포함된 모든 도큐먼트들이 있는 커서 반환 -->
{배열 필드 : {"$all" : [배열요소들]}}
<!-- ex code : 배열 필드의 요소와 순서가 정확히 일치하는 배열을 가진 도큐먼트 찾기-->
{배열 필드 : {[배열요소들]}}
<!-- ex code : 지정된 배열 필드에 주어진 요소가 포함된 모든 도큐먼트 찾기-->
{배열 필드 : {문자열}}
배열 연산자 + Projection
Projection : find의 두 번째 인자. Projection을 사용하면 현재 관심있는 필드만 결과로 가져올 수 있음
<!-- syntax -->
db.컬렉션이름.find(
{"필드명" : 1번 째인자 조건, 2번째 인자 프로젝션 }.pretty()
// 조건으로 필터링하고 프로젝션만 가져오기
<!-- ex code -->
db.listingAndReviews.find(
{"amenities" : { "$size" : 20,
"$all" : ["internet, "wifi", ...]}},
{"price" : 1, "address" : 1}).pretty()
// 조건으로 필터링하고 price와 address만 출력
<!-- Projection Syntax -->
db.컬렉션이름.fint({쿼리}, {프로젝션})
필드 : 1 - 지정한 필드 포함
필드 : 0 - 지정한 필드 제외
// 프로젝션을 사용할 때 값을 1 또는 0만 일관되게 사용하여 작성
db.컬렉션이름.fint({쿼리}, {필드1 : 1, 필드2 : 1})
db.컬렉션이름.fint({쿼리}, {필드1 : 0, 필드2 : 0})
// 프로젝션의 값을 일관되지 않게 사용하면 안된다.
db.컬렉션이름.fint({쿼리}, {필드1 : 0, 필드2 : 1})
// 단, 예외적으로 _id의 경우 0과 1을 혼용하여 사용 가능
db.컬렉션이름.fint({쿼리}, {_id : 0, 필드2 : 1})
고급 프로젝션 : $eleMatch(프로젝션) / $eleMatch(쿼리)
<!-- syntax -->
{ 필드 : {"$eleMatch" : {필드:값}}}
- $elMatch(쿼리)
쿼리의 프로젝션 뿐만 아니라 find 명령의 쿼리 부분에서도 사용 가능
$eleMatch가 첫번째 인자에 쓰일 경우, 배열 필드의 서브 도큐먼트 필드가 쿼리와 일치하는 문서 찾기
- $elMatch(프로젝션)
지정한 배열 필드가 도큐먼트에 존재하고 조건에 맞는 요소가 있는 경우에만 해당 필드를 결과에 포함.
$eleMatch가 두번째 인자에 쓰일 경우, 지정된 기준과 일치하는 요소가 하나 이상 있는 배열요소만 프로젝션
